

- Дартмутская конференция.
- Перцептрон.
- Бум искусственного интеллекта 1960-х годов.
- Искусственный интеллект-зима. 1980-е годы.
- Искусственный интеллект. Развитие экспертных систем.
- Появление НЛП и компьютерного зрения в 1990-е годы.
- Рост больших данных.
- Искусственный интеллект и глубокое обучение.
- Развитие генеративного искусственного интеллекта.
Дартмутская конференция.
Дартмутская конференция 1956 года — знаковое событие в истории искусственного интеллекта. Это был летний исследовательский проект, который состоялся в 1956 году в Дартмутском колледже в Нью-Гэмпшире, США.
Конференция была первой в своем роде, в том смысле, что она собрала вместе исследователей из, казалось бы, разных областей – информатики, математики, физики и других – с единственной целью изучить потенциал синтетического интеллекта (термин ИИ еще не существовал).
Среди участников были Джон Маккарти , Марвин Мински и другие видные учёные и исследователи.
В ходе конференции участники обсудили широкий спектр тем, связанных с ИИ, таких как обработка естественного языка, решение проблем и машинное обучение. Они также изложили план исследований в области искусственного интеллекта, включая разработку языков программирования и алгоритмов для создания интеллектуальных машин.
Эта конференция считается поворотным моментом в истории искусственного интеллекта, поскольку она ознаменовала зарождение этой области и момент, когда было введено название «искусственный интеллект».
Дартмутская конференция оказала значительное влияние на общую историю искусственного интеллекта. Это помогло утвердить ИИ как область исследования и стимулировало разработку новых технологий и методов.
Участники изложили видение ИИ, которое включало создание интеллектуальных машин, которые могли бы рассуждать, учиться и общаться, как люди. Это видение вызвало волну исследований и инноваций в этой области.
После конференции Джон Маккарти и его коллеги приступили к разработке первого языка программирования искусственного интеллекта — LISP . Этот язык стал основой разработки ИИ и существует до сих пор.
Конференция также привела к созданию научных лабораторий искусственного интеллекта в нескольких университетах и исследовательских институтах, включая Массачусетский технологический институт , Карнеги-Меллон и Стэнфорд .
Одним из наиболее значительных наследий Дартмутской конференции является разработка теста Тьюринга .
Алан Тьюринг , британский математик, предложил идею теста, чтобы определить, может ли машина демонстрировать разумное поведение, неотличимое от человеческого.
Эта концепция обсуждалась на конференции и стала центральной идеей в области исследований ИИ. Сегодня тест Тьюринга остается важным ориентиром для измерения прогресса исследований ИИ.
Дартмутская конференция стала поворотным событием в истории искусственного интеллекта. Она сделала ИИ областью исследований, определила направление работ и вызвала волну инноваций в этой области. Наследие конференции можно увидеть в разработке языков программирования искусственного интеллекта, появлению исследовательских лабораторий и тесте Тьюринга.
Перцептрон.
Перцептрон — это архитектура искусственной нейронной сети, разработанная психологом Фрэнком Розенблаттом в 1958 году. Она положила начало так называемому подходу к искусственному интеллекту, основанному на мозге.
Перцептро́н (или персептрон[nb 1] (англ. perceptron от лат. perceptio — восприятие; нем. Perzeptron)) — математическая или компьютерная модель восприятия информации мозгом (кибернетическая модель мозга), предложенная Фрэнком Розенблаттом в 1957 году и впервые реализованная в виде электронной машины «Марк-1»[nb 2] в 1960 году. ru.wikipedia.org
С технической точки зрения, перцептрон — это двоичный интерпретатор, который может научиться классифицировать входные шаблоны на две категории. Он работает, беря набор входных значений и вычисляя взвешенную сумму этих значений, а затем пороговую функцию, которая определяет, равен ли выходной сигнал 1 или 0. Итоги корректируются в процессе обучения, чтобы оптимизировать производительность классификатора.
Перцептрон считался важной вехой в развитии искусственного интеллекта, поскольку он продемонстрировал потенциал алгоритмов машинного обучения для имитации человеческого интеллекта. Он показал, что машины могут учиться на собственном опыте и со временем улучшать свою производительность, как это делают люди.
Перцептрон имел большое значение еще и потому, что стал следующей важной вехой после Дартмутской конференции. Конференция вызвала большой ажиотаж по поводу потенциала ИИ, но это все еще была в основном теоретическая концепция. Перцептрон, с другой стороны, был практической реализацией ИИ, показавшей, что эту концепцию можно превратить в работающую систему.
Первоначально «Перцептрон» рекламировался как прорыв в области искусственного интеллекта и привлек большое внимание средств массовой информации. Но позже выяснилось, что алгоритм имеет ограничения, особенно когда дело касается классификации сложных данных. Это привело к снижению интереса к исследованиям перцептрона и искусственного интеллекта в целом в конце 1960-х и 1970-х годах.
В последствии перцептрон был возрожден и включен в более сложные нейронные сети, что привело к развитию глубокого обучения и других форм современного машинного обучения.
Сегодня перцептрон рассматривается как важная веха в истории искусственного интеллекта, и его продолжают изучать и использовать в исследованиях и разработках новых технологий искусственного интеллекта.
Бум искусственного интеллекта 1960-х годов.
Как мы говорили ранее, 1950-е годы стали знаменательным десятилетием для сообщества искусственного интеллекта благодаря созданию и популяризации искусственной нейронной сети «Перцептрон». Он считался прорывом в исследованиях искусственного интеллекта и вызвал большой интерес к этой области. Это послужило стимулятором того, что стало известно как AI BOOM.
Бум искусственного интеллекта 1960-х годов был периодом значительного прогресса и интереса к развитию (ИИ). Это было время, когда ученые-компьютерщики и исследователи разрабатывали новые методы создания интеллектуальных машин и программирования их для выполнения задач, которые традиционно считались требующими человеческого интеллекта.
В 1960-х годах были обнаружены очевидные недостатки перцептрона, и исследователи начали изучать другие подходы к искусственному интеллекту. Они сосредоточились на таких областях, как символическое мышление, обработка естественного языка и машинное обучение.
Эти исследования привели к разработке новых языков программирования и инструментов, таких как LISP и Prolog , специально разработанных для приложений искусственного интеллекта. Данные инструменты облегчили исследователям эксперименты с новыми методами искусственного интеллекта и разработку более сложных систем.
1961: Джеймс Слэгл, учёный-компьютерщик и профессор, разработал SAINT (Symbolic Auto INTegrator), эвристическую программу решения задач. фокусом которой была символическая интеграция в исчислении первокурсников.
1964: Дэниел Боброу, ученый-компьютерщик, создал STUDENT, первую программу искусственного интеллекта, написанную на Lisp и решающую алгебраические задачи со словами. STUDENT считается ранней вехой в области обработки естественного языка ИИ.
1965: Джозеф Вайценбаум, ученый-компьютерщик и профессор, разработал ELIZA, интерактивную компьютерную программу, которая могла функционально общаться с человеком на английском языке. Целью Вайценбаума было продемонстрировать, что общение между искусственным и человеческим разумом было «поверхностным», но он обнаружил, что многие люди приписывали ELIZA антропоморфные характеристики.
1966: Робот Шейки, разработанный Чарльзом Розеном при помощи еще 11 человек, стал первым мобильным роботом общего назначения, также известным как «первый электронный человек».
1968: Терри Виноград, профессор информатики, создал SHRDLU, первую компьютерную программу на естественном языке.
Бум ИИ 1960-х годов завершился разработкой нескольких знаковых систем. Одним из примеров является программа общего решения проблем (GPS) , созданная Гербертом Саймоном, Дж. К. Шоу и Алленом Ньюэллом. GPS была ранней системой искусственного интеллекта, которая могла решать проблемы, просматривая пространство возможных решений.
Другим примером является программа ELIZA , созданная Джозефом Вайценбаумом, она представляла собой средство обработки естественного языка, имитирующее работу психотерапевта.
Бум 1960-х годов был периодом значительного прогресса в исследованиях и разработках искусственного интеллекта. Это было время, когда исследователи изучали новые подходы, разрабатывали новые языки программирования и инструменты, специально предназначенные для приложений искусственного интеллекта. Это исследование привело к разработке нескольких знаковых систем, проложивших путь к будущему развитию ИИ.
Искусственный интеллект-зима. 1980-е годы.
Зима ИИ 1980-х годов относится к периоду времени, когда исследования и разработки в этой области переживали значительный спад. Этот период застоя, с 1974 по 1993 год, наступил после десятилетия значительного прогресса в исследованиях и разработках ИИ.
Частично это произошло потому, что многие проекты, разработанные во время бума ИИ, не оправдали надежд. Исследовательское сообщество все больше разочаровывалось в отсутствии прогресса. Это привело к сокращению финансирования, и многие исследователи были вынуждены отказаться от своих задумок и вообще покинуть эту область.
Согласно отчету Лайтхилла из Комиссии по научным исследованиям Великобритании, учёные не смогли достичь своих грандиозных целей, ни в одной части этой области. Открытия, сделанные до сих пор, не оказали такого значительного влияния, которое было обещано.
Зима искусственного интеллекта 1980-х годов характеризовалась значительным сокращением финансирования исследований в области искусственного интеллекта и общим отсутствием интереса к этой теме среди инвесторов и общественности. Это привело к значительному сокращению количества разрабатываемых проектов ИИ, а многие исследователи, которые все еще были активны, не смогли добиться значительного прогресса из-за нехватки ресурсов.
Несмотря на проблемы зимы искусственного интеллекта, данная сфера не исчезла полностью. Многие продолжали работать над проектами ИИ и добились важных успехов, включая разработку нейронных сетей и начала машинного обучения. Но прогресс был медленным, и только в 1990-х годах интерес к ИИ начал снова возрастать.
Искусственный интеллект. Развитие экспертных систем.
Экспертные системы — это разновидность технологии искусственного интеллекта, разработанная в 1980-х годах. Экспертные системы предназначены для имитации способностей человека-эксперта принимать решения в определенной области, например, в медицине, финансах или инженерии.
В 1960-х и начале 1970-х годов вокруг искусственного интеллекта и его потенциала в различных отраслях было много оптимизма и волнения. Но, как уже говорилось, этот энтузиазм был подорван периодом спада и отсутствием финансирования.
Развитие экспертных систем стало поворотным моментом в истории ИИ. Давление на сообщество искусственного интеллекта возросло вместе с требованием предоставить практические, масштабируемые, надежные и поддающиеся количественной оценке применения.
Экспертные системы послужили доказательством того, что системы искусственного интеллекта могут использоваться в реальных условиях и потенциально способны принести значительные выгоды предприятиям и отраслям. Экспертные системы использовались для автоматизации процессов принятия решений в различных областях: от диагностики заболеваний до прогнозирования цен на акции.
С технической точки зрения экспертные системы обычно состоят из базы знаний, которая содержит информацию о конкретной области, и механизма вывода, который использует эту информацию для обработки и принятия решений. Экспертные системы также включают в себя различные формы рассуждения, такие как дедукция, индукция и абдукция, для моделирования процессов принятия решений людьми-экспертами.
Сегодня экспертные системы продолжают использоваться в различных отраслях, а их развитие привело к созданию других технологий искусственного интеллекта, таких как машинное обучение и обработка естественного языка.
Появление НЛП и компьютерного зрения в 1990-е годы.
В 1990-е годы исследования ИИ и глобализация начали набирать обороты. Этот период положил начало современной эпохе исследований искусственного интеллекта.
Как говорилось ранее, экспертные системы появились примерно в конце 1980-х — начале 1990-х годов. Но они были ограничены тем фактом, что полагались на структурированные данные и логику, основанную на правилах. Они изо всех сил пытались обрабатывать неструктурированные данные, такие как текст на естественном языке или изображения, которые по своей сути неоднозначны и зависят от контекста.
Чтобы устранить это ограничение, исследователи начали разрабатывать методы обработки естественного языка и визуальной информации.
В 1970-х и 1980-х годах был достигнут значительный прогресс в разработке основанных на правилах систем НЛП и компьютерного зрения. Но эти системы по-прежнему были ограничены тем фактом, что они полагались на заранее определенные правила и не могли учиться на данных.
В 1990-х годах достижения в области алгоритмов машинного обучения и вычислительной мощности привели к разработке более сложных систем НЛП и компьютерного зрения.
Исследователи начали использовать статистические методы для изучения закономерностей и особенностей непосредственно на основе данных, а не полагаться на заранее определенные правила. Этот подход, известный как машинное обучение, позволил создать более точные и гибкие модели обработки естественного языка и визуальной информации.
Одной из наиболее значительных вех этой эпохи стала разработка скрытой марковской модели (HMM), которая позволяла вероятностно моделировать текст на естественном языке. Это привело к значительному прогрессу в распознавании речи, языковом переводе и классификации текста.
Аналогичным образом, в области компьютерного зрения появление сверточных нейронных сетей (CNN) позволило более точно распознавать объекты и классифицировать изображения.
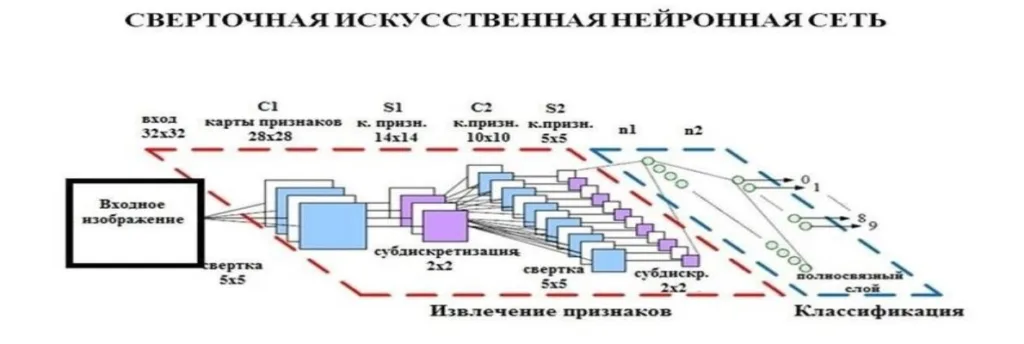
Эти методы сейчас используются в широком спектре: от беспилотных автомобилей до медицинской визуализации.
Появление НЛП и компьютерного зрения в 1990-х годах стало важной вехой в истории искусственного интеллекта. Они позволили производить более сложную и гибкую обработку неструктурированных данных.
Рост больших данных.
Концепция больших данных существует уже несколько десятилетий, но ее рост в контексте искусственного интеллекта прослеживается с начала 2000-х годов. Прежде чем мы углубимся в то, как это связано с ИИ, давайте кратко обсудим термин «большие данные».
Чтобы данные можно было назвать большими, они должны соответствовать 3 основным атрибутам: объем, скорость и разнообразие.
Под объемом понимается размер набора данных, который может варьироваться от терабайтов до петабайтов и больше.
Скорость относится к скорости, с которой данные генерируются и должны быть обработаны. Например, данные из социальных сетей или устройств Интернета вещей могут генерироваться в режиме реального времени и требуют быстрой обработки.
Под разнообразием подразумеваются различные типы генерируемых данных, включая структурированные, неструктурированные и полуструктурированные.
До появления больших данных ИИ был ограничен количеством и качеством информации, доступной для обучения и тестирования алгоритмов машинного обучения.
Обработка естественного языка (НЛП) и компьютерное зрение были двумя областями ИИ, в которых в 1990-е годы наблюдался значительный прогресс, но они все еще были ограничены объемом доступных данных.
Например, ранние системы НЛП были основаны на правилах, созданных вручную, которые были ограничены в своей способности справляться со сложностью и изменчивостью естественного языка.
Рост больших данных изменил ситуацию, предоставив доступ к огромным объемам из самых разных источников, включая социальные сети, датчики и другие подключенные устройства. Это позволило алгоритмам машинного обучения обучаться на гораздо больших наборах данных, что, в свою очередь, позволило им осваивать более сложные закономерности и делать более точные прогнозы.
В то же время достижения в технологиях хранения и обработки данных, такие как Hadoop и Spark, позволили быстро и эффективно обрабатывать, и анализировать эти большие объёмы. Это привело к разработке новых алгоритмов машинного обучения, таких как глубокое обучение, которые способны обучаться на огромных кластерах информации и делать высокоточные прогнозы.
Сегодня большие данные продолжают оставаться движущей силой многих последних достижений в области искусственного интеллекта, от автономных транспортных средств и персонализированной медицины до систем понимания естественного языка и рекомендаций.
Поскольку объем генерируемых данных продолжает расти в геометрической прогрессии, роль больших данных в ИИ в ближайшие годы станет только более важной.
Искусственный интеллект и глубокое обучение.

Появление глубокого обучения является важной вехой в глобализации современного искусственного интеллекта.
Со времени Дартмутской конференции 1950-х годов ИИ был признан законной областью исследований, и первые годы исследований были сосредоточены на символической логике и системах, основанных на правилах. Это включало ручное программирование машин для принятия решений на основе набора заранее определенных правил. Хотя эти системы были полезны в определенных приложениях, их способность учиться и адаптироваться к новым данным была ограничена.
Лишь после появления больших данных глубокое обучение стало важной вехой в истории искусственного интеллекта. В условиях экспоненциального роста объема доступной информации исследователям потребовались новые способы обработки и извлечения данных из огромных объемов.
Алгоритмы глубокого обучения решили эту проблему, позволив машинам автоматически обучаться на больших наборах данных и делать прогнозы или принимать решения на основе этого обучения.
Глубокое обучение — это тип машинного обучения , в котором используются искусственные нейронные сети, моделирующие структуру и функции человеческого мозга. Эти сети состоят из слоев взаимосвязанных узлов, каждый из которых выполняет определенную математическую функцию над входными данными. Выходные данные одного слоя служат входными данными для следующего, позволяя сети извлекать из них все более сложные функции.
Одним из ключевых преимуществ глубокого обучения является его способность изучать иерархические представления. Это означает, что сеть может автоматически научиться распознавать закономерности и особенности на разных уровнях абстракции.
Например, сеть глубокого обучения может научиться распознавать форму отдельных букв, затем структуру слов и, наконец, значение предложений.
Развитие глубокого обучения привело к значительным прорывам в таких областях, как компьютерное зрение, распознавание речи и обработка естественного языка. Например, алгоритмы глубокого обучения теперь способны точно классифицировать изображения, распознавать речь и даже генерировать реалистичный человеческий язык.
Глубокое обучение представляет собой важную веху в истории искусственного интеллекта, ставшую возможной благодаря появлению больших данных. Способность автоматически обучаться на огромных объемах информации привела к стремительному прогрессу в широком спектре приложений, и, вероятно, оно продолжит оставаться ключевой областью исследований и разработок в ближайшие годы.
Развитие генеративного искусственного интеллекта.
Генеративный ИИ — это подобласть искусственного интеллекта, которая предполагает создание систем, способных генерировать новые данные или контент, похожий на данные, на которых он обучался. Это может включать в себя создание изображений, текста, музыки, видео. Вот где мы находимся на текущей временной шкале искусственного интеллекта.
В контексте истории генеративный ИИ можно рассматривать как важную веху, наступившую после появления глубокого обучения.
Ещё одна подобласть искусственного интеллекта - трансформеры, этот тип архитектуры нейронных сетей, произвёл революцию в генеративном искусственном интеллекте. Он был представлен в статье Васвани и др . в 2017 году и с тех пор используется в различных задачах, включая обработку естественного языка, распознавание изображений и синтез речи.
Трансформеры используют механизмы самообслуживания для анализа взаимосвязей между различными элементами последовательности, что позволяет им генерировать более последовательный и детальный результат. Это привело к разработке больших языковых моделей, таких как GPT-4 ChatGPT , которые могут генерировать человеческий текст по широкому кругу тем.
Искусство — еще одна область, где генеративный ИИ оказал значительное влияние. Обучая модели глубокого обучения на больших наборах произведений, генеративный ИИ может создавать новые и уникальные изображения.

Использование генеративного ИИ в искусстве вызвало споры о природе творчества и авторства, а также об этичности использования ИИ для создания произведений. Некоторые утверждают, что картины, созданные искусственным интеллектом, не являются по-настоящему творческими, поскольку ему не хватает преднамеренности и эмоционального резонанса, свойственного искусству, созданному человеком. Другие утверждают, что искусство ИИ имеет свою ценность и может использоваться для исследования новых форм творчества.
Большие языковые модели, такие как GPT-4, также использовались в области творческого письма, причем некоторые авторы применяли их для создания нового текста или в качестве инструмента для вдохновения.

Это подняло вопросы о будущем письма и роли ИИ в творческом процессе. Некоторые утверждают, что тексту, созданному ИИ, не хватает глубины и нюансов человеческого письма, другие видят в нем инструмент, который может повысить творческий потенциал человека, предоставляя новые идеи и перспективы.
Генеративный искусственный интеллект, особенно с помощью трансформеров и больших языковых моделей, может произвести революцию во многих областях, от искусства до письма и моделирования. Хотя до сих пор ведутся споры о природе творчества и этичности использования ИИ в этих областях, ясно, что генеративный ИИ — это мощный инструмент, который продолжит формировать будущее технологий и искусства.
Но с такими приложениями, как ChatGPT, Dalle.E и т.д., мы лишь поверхностно коснулись возможных применений ИИ. Есть проблемы, и их определенно будет больше.
Вопросы конфиденциальности данных, этики использования ИИ и его потенциального влияния на рабочие места становятся все более актуальными. По мнению многих экспертов, необходимо уделять больше внимание разработке этических норм и регуляторных политик для обеспечения безопасности и честного использования ИИ.







